

●Payment







SuperTrend AIインジケーターは、K-meansクラスタリング機械学習手法とテクニカルインジケーターのギャップを埋める新しいアプローチです。この場合、著名なSuperTrendインジケーターにK-Meansクラスタリングを適用します。
使用法
ユーザーは、SuperTrend AIトレーリングストップを通常のSuperTrendインジケーターと同様に解釈できます。より高い最小/最大ファクターを使用すると、長期的なシグナルが返されます。(画像1)
各シグナルに表示されるパフォーマンスメトリックは、インジケーターのより深い解釈を可能にします。より高い値は、1や0のような低い値のシグナルと比較して、市場がトレンドの方向に向かう可能性が高いことを示す可能性があります。(画像2)
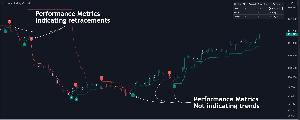
上の画像では、トレンドを示すシグナルにおけるパフォーマンスメトリックのより明確な例を確認できますが、これらのパフォーマンスメトリックはすべてのシグナルを信頼性高く予測することはできません。(画像3)
上の画像では、トレーリングストップとその適応移動平均がサポートとレジスタンスとしても機能することがわかります。より高い値の パフォーマンスメモリ 設定を使用すると、返されたトレーリングストップの長期的な適応移動平均を取得できます。
詳細
K-Meansクラスタリング(画像4)
データ内のクラスターを見つけるためのさまざまな方法が存在し、このスクリプトで使用されているのは K-Meansクラスタリング、ユーザーが設定した数のクラスターを見つけるシンプルな反復的な教師なしクラスタリング手法です。
K-Meansアルゴリズムの単純な形式は、次の手順を実行して K クラスターを見つけます:
- (1) 検出するクラスターの数(K)を決定します。
- (2) ランダムな値でKセントロイド(クラスター中心)を初期化します。
- (3) データポイントをループし、各データポイントから最も近いセントロイドを決定し、そのデータポイントをセントロイドに関連付けます。
- (4) 特定のセントロイドに関連付けられたデータポイントの平均を取ることでセントロイドを更新します。
- 収束するまで、つまりセントロイドがもはや変わらなくなるまで、ステップ3から4を繰り返します。
K-Meansがどのように機能するかをグラフィカルに説明するために、2つの明らかなクラスターを持つ1次元データセットの例を考えましょう:(画像5)
これはもちろん単純なシナリオですが、 K は一般的により高く、データポイントの数も多くなります。この方法はセントロイドの初期化に非常に敏感であるため、一般的には複数回実行され、最良のセントロイドを返す実行を保持します。K-Meansを使用した適応SuperTrendファクター
提案されたインジケーターの理論は、次の仮説に基づいています:
異なる設定を使用したインジケーターの複数のインスタンスがある場合、時刻 t における最適な設定の選択は、設定 s(t)を持つ最もパフォーマンスの良いインスタンスによって与えられます。
時刻 t における最良の設定を使用してインジケーターの計算を行うと、その特性がパフォーマンスに基づいて適応するインジケーターが返されます。しかし、最もパフォーマンスの良いインスタンスと2番目にパフォーマンスの良いインスタンスの設定に高い差異がある場合、パフォーマンスに大きな違いがない場合はどうでしょうか?この特定のケースは稀ですが、特定の設定のグループでパフォーマンスが似ているのを見ることは珍しくありません(これはパラメータ最適化ヒートマップで観察できます)。そのため、望ましい設定をフィルタリングして最もパフォーマンスの良いものだけを使用することは厳しすぎるように思えます。したがって、最初の仮説を再定式化できます:
この特定のケースは稀ですが、特定の設定のグループでパフォーマンスが似ているのを見ることは珍しくありません(これはパラメータ最適化ヒートマップで観察できます)。そのため、望ましい設定をフィルタリングして最もパフォーマンスの良いものだけを使用することは厳しすぎるように思えます。したがって、最初の仮説を再定式化できます:
異なる設定を使用したインジケーターの複数のインスタンスがある場合、時刻 t における最適な設定の選択は、設定 s(t)を持つ最もパフォーマンスの良いインスタンスの平均によって与えられます。
この最もパフォーマンスの良いインスタンスのグループを見つけるには、前述のK-Meansクラスタリング手法を使用し、最悪のパフォーマンス、平均的なパフォーマンス、最良のパフォーマンスの3つの関心グループ(K = 3)を定義します。
まず、パフォーマンスのアナログを取得します。 P(t, factor) は次のように説明されます:
P(t, factor) = P(t-1, factor) + α * (⌦C(t) × S(t-1, factor) - P(t-1, factor))ここで、1 >α> 0は、古い入力が現在の出力にどの程度影響を与えるかを決定するパフォーマンスメモリです。C(t)は終値であり、S(t, factor)は乗数ファクターfactorを持つSuperTrendシグナル生成関数です。
このパフォーマンス関数を複数の factor 設定で実行し、得られた複数のパフォーマンスに対してK-Meansクラスタリングを実行して、最もパフォーマンスの良いクラスターを取得します。得られたパフォーマンスの四分位数を使用してセントロイドを初期化し、セントロイドの収束を早めます。(画像6)
ユーザーが実験目的で最良、平均、または最悪のクラスターから最終ファクターを取得する自由を与えることに注意してください。
設定
- ATR長さ:SuperTrendの計算に使用されるATR期間。
- ファクター範囲:SuperTrendの計算に使用される最小および最大ファクター値を決定します。
- ステップ:ファクター範囲の増分。
- パフォーマンスメモリ:古い入力が現在の出力にどの程度影響を与えるかを決定し、高い値は長期的なパフォーマンス測定を返します。
- クラスターから:最終ファクターを取得するために使用されるクラスターを決定します。
最適化
この設定グループは、スクリプトの実行時のパフォーマンスに影響を与えます。
- 最大反復ステップ:セントロイドを見つけるために許可される最大反復回数。過度に低い値は、スクリプトの読み込み時間を改善する可能性がありますが、クラスタリングが不十分になる可能性があります。
- 履歴バー計算(ルックバック):スクリプトの計算ウィンドウ(バー単位)。500を超えるとパフォーマンスが遅くなる可能性があります。最良の結果を得るために300でテストされました。
●Payment
For those using GogoJungle for the first time Easy 3 steps to use the product!
At GogoJungle, we provide services to enrich your investment life for our members. In addition, product purchases are limited to members. Why not register as a member now and make use of GogoJungle!