
[EA制作・検証] 優位性の見つけ方
こんにちは。2payです。
最近秘密兵器(インジケータ)が完成したので、秘密兵器の紹介と優位性のあるポイントの抽出方法を紹介します。
投機において優位性を持ってトレードすることは非常に重要です。
RR1:1と仮定して、負率49%、勝率51%のような僅かな差だったとしても勝ちの割合が多いというだけで資産は増えます。
小さな勝ちの積み重ねを繰り返し実行する事で大数の法則に基づき、数学的に増えることが説明できるからです。
優位性のあるポイントを探すためのアプローチの1つとして、「時間別に優位性があるかないかを調べる」方法が挙げられます。
やり方は非常にシンプルで、バックテスト上で新しい足が出現する度にポジションを決済し、改めて新しくポジションを持ちます。
保有時間を足1本分で固定し、スケールがH1なら毎時00分にポジションの決済と新規建てを実行することになります。
そしてテスト終了時に、各時間毎、分毎、週毎、月毎、営業日数毎、ゴトー日の該当、月初・月末の該当、祝日の該当、イベントの該当...等の要因別で集計し、BuyとSellでそれぞれ結果を出力します。
pythonAPIを叩けば結果が爆速で出るような気もしますが、勉強中で上手く扱えないので、Mqlでインジケータにしてしまおうと思います。
インジケータの動作をざっくり説明すると、
①長期の4本値データを過去から現在に向かって読ませる。
②指定のエントリー時間になったらエントリーし、指定の保有時間を経過したら決済する。(=疑似バックテスト)
③バックテストを1本取り終わったら、エントリー時間と保有時間を変えて②を繰り返す。
④結果をヒートマップ化して視覚的に分布を確認できるようにする。
③の条件変えは自動化し、0~23時×保有時間1時間刻み のような具合で、総当たりでテストします。
バーはM1が最小なので、日毎に集計するとしても最大で、 1440分×1440分=2,073,600 通りの組み合わせを検証することが可能です。
テスト期間15年程度だと1本10秒程度でテストできるため、200万回テストすると240日かかる見込みです。
内部条件を変えたり通貨を変えて何度も回さないといけないので、30分刻み (48×48=2,304通り) で大まかに分布を調べ、良好なポイントだけを詳細に確認するやり方で行こうと考えています。
これくらい減らせば、日付や指標条件をいろいろ変えても3日で1通貨分まるっと調べきることができます。
その他、時間別にスプレッドを変化させたり、SL有無による成績の変化を同時に測定して有無による傾向の違いも見つけられるようにします。
後からEA化して普通のバックテストにかけるので、リアルTickデータとの乖離が小さくなるよう、事前検証の段階から負荷をかけていきます。
以下がインジケータを回した結果になります。
チャート画面上に整然と並んでいる点群は1つ1つがボタンオブジェクトになっており、クリックすると詳細なスコアを確認できるようになっています。
横軸はエントリー時刻(h)、縦軸は保有時間(h)で、それぞれ30分刻みで取得している状況です。(0時台はスプレッドが広いため、検証から除外しています。)
色はPFに基づいて染色され、灰色を損益分岐点(=1.0)とし、赤色が強いほど損失が強く、緑色が強いほど利益が高く、青色が強いほどSLを設置した場合の利益が高い事を示します。
緑色と青色は混色し、双方とも良好な結果を出している場合は水色になります。
下図の条件は"月曜のみ"で、目立った優位性はほとんど確認できません。辛うじて23時から30分間保有すると利益が取れる可能性があることが読み取れます。
右側に赤い斜線が走っていますが、スプレッドの広い0時台を跨いだタイミングが赤く出ている状況です。
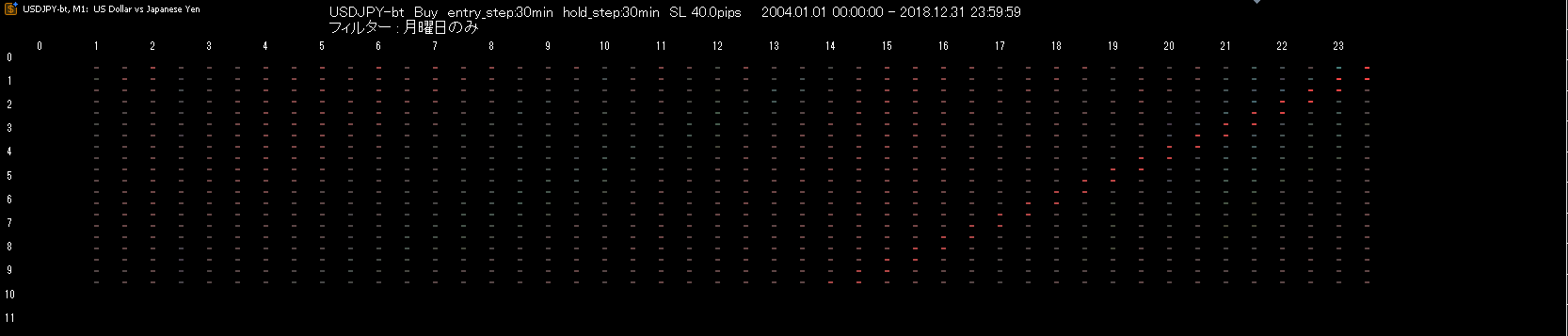
同様に"木曜日のみ"を比較して見てみます。
月曜日と比較して水色が目立つ範囲が広がったことが確認できます。
右側の赤い斜線(=0時の範囲)より下に優れた結果が集まっているということは、金曜日に勝っているという事が示唆されます。
これの正体はゴトー日で、前倒しの都合により金曜日に優位性が集中していることが曜日フィルターからも確認できるということを示しています。
また、優位性が高い(水色で染まっている)範囲が広いことが確認できるため、多くの資金、多くの投資家が注目していることが分かります。
月曜日23時のようなごく小規模な優位性は、ヘッジファンドや個人投資家等のポジション整理、リスク回避のクローズ(または両建て)、等の投資行動と推察できます。
その時の優位性の規模によって、仕掛けられる枚数の上限も調整する必要があります。
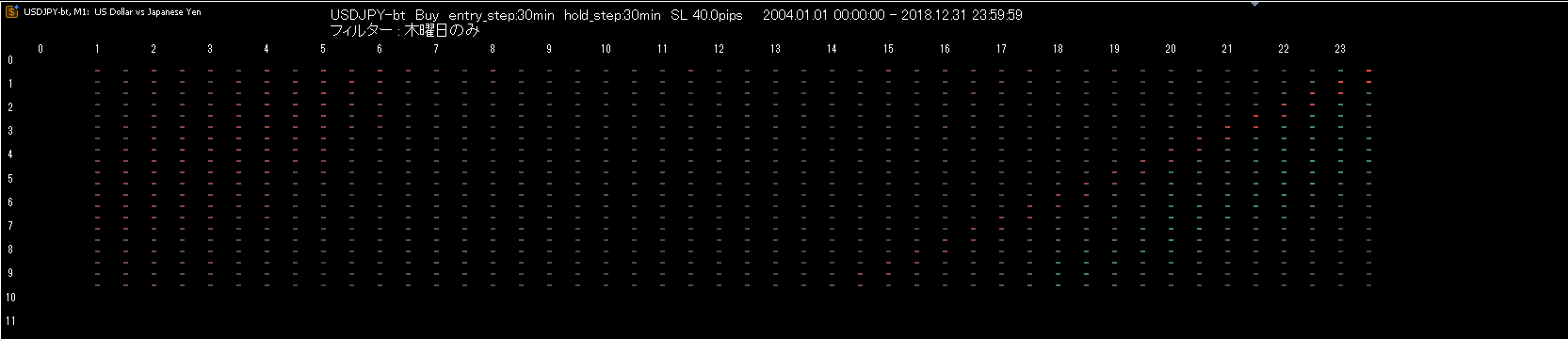
ヒートマップ出力と同時に、良好な結果をログへ出力する機能も搭載しました。
インジケータをセットして放置するだけで良好な結果が数百・数千という単位で大量に集まります。
この中から統計的に有意(ランダムではない)で、ひときわ優秀なものだけを選定したり、ポートフォリオとのリスクバランスに合ったものや、トレードスケジュール(お金の遊んでいる時間)に適合するものを選定することが可能です。
つまり真に有効かつ自身にとって都合の良いものを自由に選んで組み合わせることができるのです。
成績優秀なのに取引頻度が少ないようなものでも、10~20個 束ねればまともなポートフォリオになるはずです。
// ---
今回は優位性の見つけ方というテーマでお伝えしました。
このモデルはまだまだ単純なものに過ぎませんが、クオンツ系ファンドもこのような手順でビックデータを分析しています。
業界ではこれを機械学習で解析し、季節性や環境要因の重みづけを加えてポートフォリオに組み込んだりする一連の工程を自動化する程度のことはやっているようです。
到底そのようなレベルで実装することは叶いませんが、プロのやり方に近づける事が成功につながると思っています。
最後まで読んでいただきありがとうございました。
// ---
おまけ
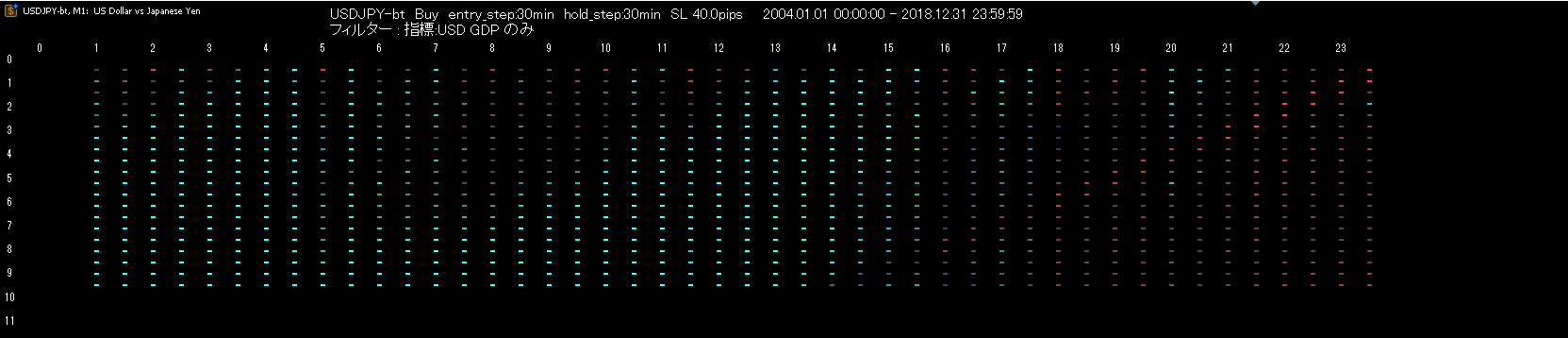
米指標GDP発表日に限定したフィルターです。
曜日フィルターと比較して圧倒的に勝っていることが分かります。(水色が濃い範囲一帯はPF2.0を超えています)
指標数値は公表する組織が異なり、それに伴って反応する投資家のタイプも変化します。
一括りにせずに1つ1つ詳らかにすることで市場のノイズが薄くなり、周期性が浮かび上がってきます。
様々なタイプの投資家がそれぞれの周期で取引を行い、タイミングが重なったり重ならなかったりする過程の積み重ねが市場をランダムにしているのです。
ソブリンや実需筋はカレンダーの変則的な規則に従って行動するため、フーリエ変換のような単純な周期解析では優位性が顕在しません。
// ---
おまけ2
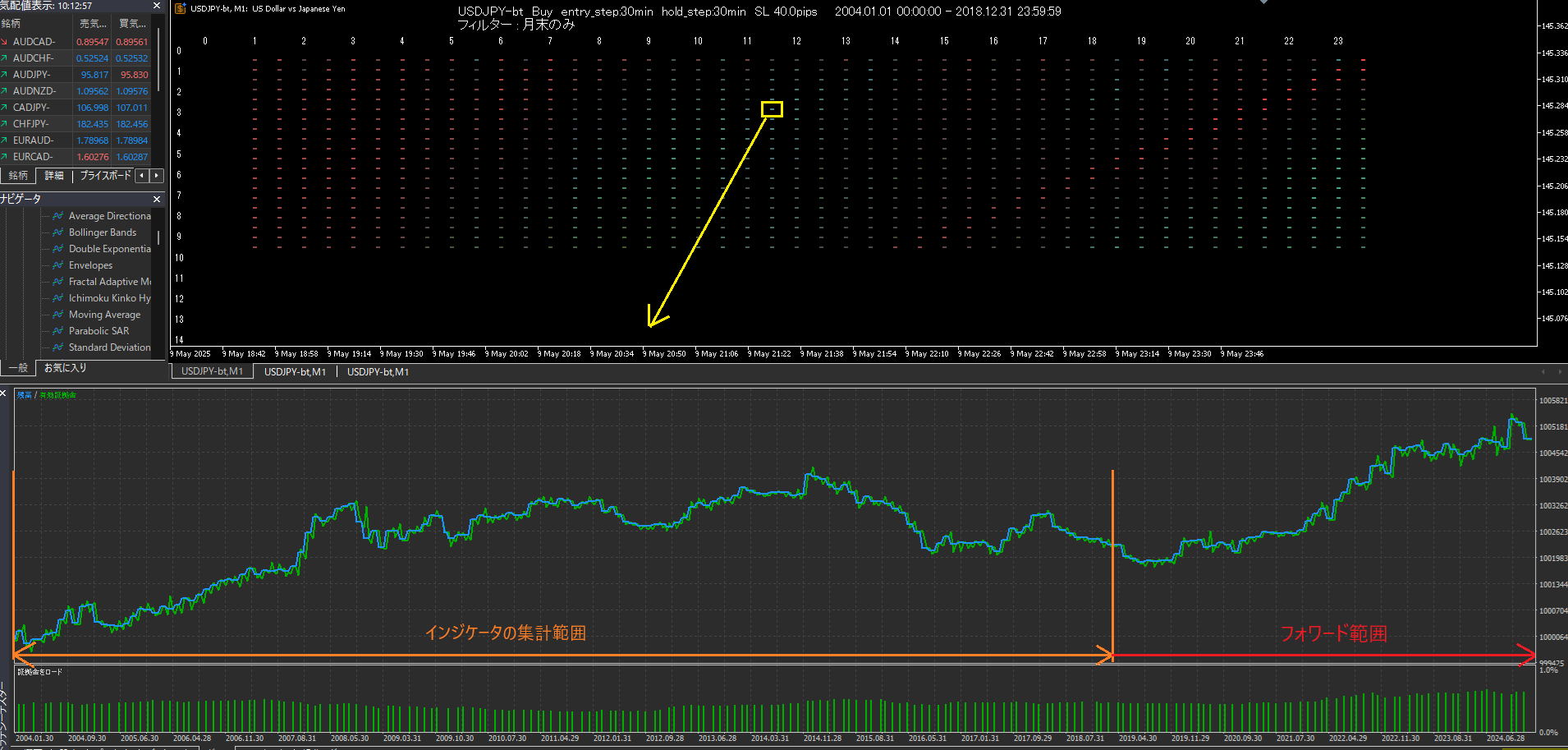
月末に限定したフィルターです。
東京時間に売り傾向、ユーロ時間に買い傾向が出ています。
資産曲線の荒れ具合も確認したいので、ひとつEA化してバックテストを取ってみます。
インジケータはあえて途中までしか集計せず、残りの期間をフォワード期間として使えるように残しました。
2015~2021年の落ち込んでいる時期がありますが、全体としてみれば増えていることが分かります。
この分析段階では "傾向がある(優位性が認められる)" という事実さえあれば十分です。
要はこの時間は上昇しやすい背景を持っているということなので、売りポジションを入れない、押したら買う、インジケータのGCサインが出たら買う、等の戦術がかみ合いやすくなります。

Is it OK?