

「EAの最適化と学習の違い」(1/12)投資AI開発奮闘記
2022年はMT5で最適化をするのが流行ってましたね
2023年は最適化しすぎによる過剰最適化が壁となり最適化のブームは去ったように感じます
僕ももれなく過剰最適化の壁に挫折した一人でもあります
EAにはロジック部分とシステム部分があると考えてて
ロジック部分は最適化厳禁、システム部分は最適化OKというマイルールがあります
システムっていうのはナンピンのルールとかマーチンの倍率とかエントリーポイントではない部分です
まぁ厳密には、、、カーブフィッティング起こしちゃうんですけどねw
最適化の話はおいといて、
今は学習に重点を置いてます。
学習曲線の概要
最適化と学習は一見似ていますが、大きな違いがあります。
以下の画像は、あるディープラーニングモデルの損失曲線(左)と精度曲線(右)を示しています。
のグラフをもとに、EAの最適化と学習について話をしていきますね
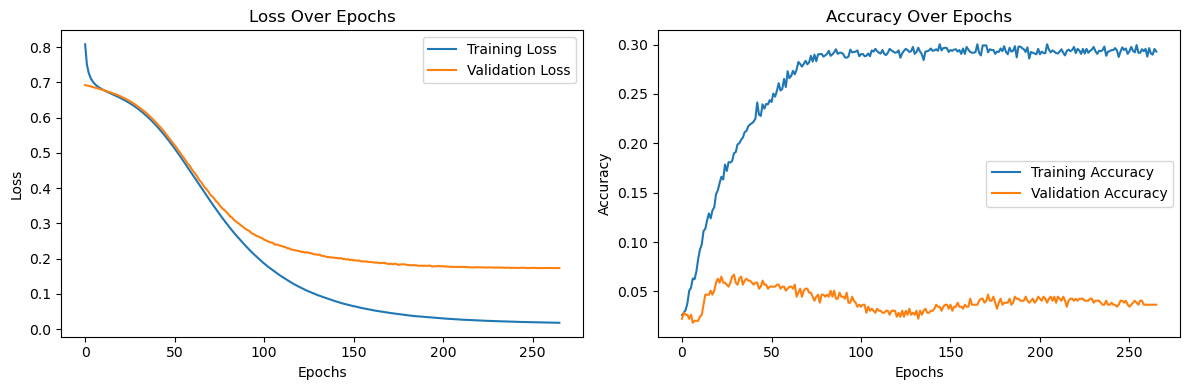
損失曲線にはトレーニング(青)とバリデーション(オレンジ)の曲線があります
縦軸は損失(テストの減点みたいなもの)、横軸は学習回数(授業の回数みたいなもの)です
学習回数を重ねると損失が減っていきますが、バリデーションは途中で損失が減らなくなります
授業を何回受けてもテストで100点は取れないようなイメージです
EAでいうと最適化がトレーニング、フォワードがバリデーションというイメージになります。
精度曲線も同じくトレーニング(青)とバリデーション(オレンジ)の曲線があります
損失が点数だったの対して、精度は合格する確率みたいな感じです。
損失は定量的なもの、精度は定性的なものになります
最適化と学習の似ているところ
さらに学習を重ねていくと、損失は逆に大きくなっていくことがあります。
これを過学習といいます。
最適化も同様にパラメーターを細かく決めすぎると将来のデータに適合できなくります。
そのため最適化期間とは別にフォワードテスト部分を用意するのですが
フォワードテスト部分をよくすると、今度はフォワードテスト部分にフィットしていきます
過剰最適化、過学習のイメージは以下になります
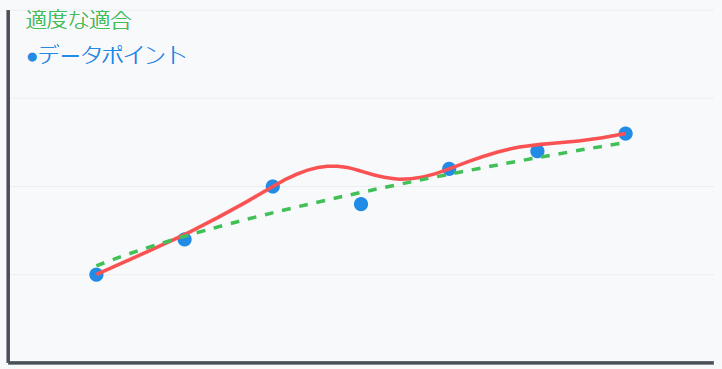
ブロットには誤差があります、これは市場のノイズになります。
ノイズとは再現性のない値動きです。
このノイズを拾うことで、どんどん適切な曲線から逸脱していくことになります。
プロットの回数を減らして適度な解の曲線を作成することが必要になります
最適化と学習の違い
以上のことから、最適化をしても本来の曲線の位置がわからず、最適化の評価が難しいのですが、
学習は損失曲線を描画することができ、適切な回数で止めることが可能です。
ノイズを拾って結果がよくなることを抑えることができ、未知データに対応しやすくなります。
この未知データに対応しやすくなる能力のことを汎化性能といいます。
よくEAの賞味期限という表現をすることがありますが、この汎化性能の評価をすることができれば
EAの賞味期限を長く保つことができるのです
さらに最適化する項目が多ければ多いほどカーブフィッティングを引き起こしガチになってきますが、
学習の場合は、項目(特徴量)が多ければ多いほど、細かい相場を学習することができるようになります。
具体的な学習例
一般的なEAを作成する際、インジケーターは多くても10種類程度でしょう。
それも、シフトは1,2,3あたりが多いかなと思います。
インジケーター10種類×3シフト=30個
多くてもこの程度ですし、すべてを最適化対象にするとあっという間に過剰最適化になってしまいます
今現在私が特徴量としているのは、インジケーターで300種類、シフトも1~200なので・・・
6万個というデータを使用して相場を予測している状態になります
データを集めるのが大変です。
最適化の課題を機械学習によって解決しつつ、強いEAを作ることを目指しています。







Is it OK?